
“การใส่ข้อมูลสินค้าซ้ำ” เป็นปัญหาที่มักจะพบในระบบ e-Commerce โดยเฉพาะเมื่อมีฐานข้อมูลสินค้าขนาดใหญ่ หรือมีวิธีการเพิ่มข้อมูลในระบบหลายแบบ หรือมีผู้ที่มีสิทธิ์ใส่ข้อมูลหลายคน
เพราะการใส่ข้อมูลมีโอกาสเกิดความผิดพลาดได้ง่าย การใส่ข้อมูลที่ผิดนิดเดียว ส่งผลให้ระบบมองว่าเป็นสินค้าที่ต่างกัน ถึงแม้จริงๆ แล้วจะเป็นสินค้าตัวเดียวกันก็ตาม
เช่น “เสื้อยืดสีเทา” หรือ “เสื้อยืดแบบมีสไตล์สีเทาเข้ม” ทั้งสองมีชื่อที่แตกต่างกัน แต่หมายถึงสินค้าตัวเดียวกัน ถึงแม้จะมีการใช้รหัสสินค้าเพื่อระบุตัวตน แต่ก็อาจจะไม่ครอบคลุมหรือถูกต้อง 100%
ปัญหานี้ไม่เพียงแต่จะกระทบต่อการเก็บข้อมูลเท่านั้น ยังทำให้เกิดการแนะนำสินค้าซ้ำกันให้ลูกค้าอีกด้วย
นอกจากความยากในการเปรียบเทียบที่ได้กล่าวมาข้างต้นแล้ว จำนวนสินค้าก็มีผลต่อตรวจสอบ
โดยในสินค้าจำนวน n ชิ้น จะต้องมีการเปรียบเทียบ n!/2!(n-2)! ครั้ง หมายความว่าสินค้า 1,000 ชิ้น จะต้องเกิดการเปรียบเทียบ 499,500 ครั้ง
นั่นจึงทำให้ระบบ e-Commerce จำเป็นต้องมีระบบการตรวจสอบสินค้าที่ซ้ำกันเพื่อแก้ปัญหานี้
SIMILAR PRODUCT API: ลดความซ้ำซ้อนข้อมูลสินค้า
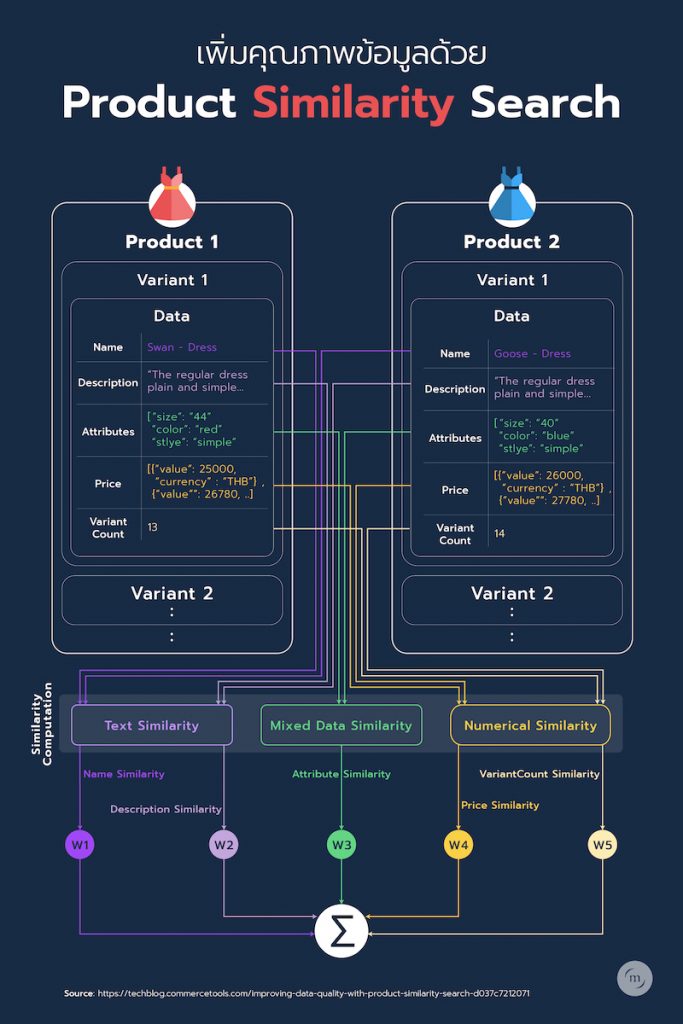
เครื่องมือหนึ่งที่น่าสนใจ คือ Similar Product API ของ Commercetools ซึ่งมีไว้สำหรับตรวจสอบสินค้าทั้งหมดในฐานข้อมูล เพื่อหาค่าความคล้ายคลึง (similarity) ระหว่างแต่ละสินค้า
โดยใช้ข้อมูลชื่อสินค้า รายละเอียด ราคา จำนวนรุ่น ฯลฯ ในการเปรียบเทียบ ข้อมูลเหล่านี้จะถูกเก็บในรูปแบบข้อมูลที่ต่างกัน
ชื่อสินค้าและรายละเอียดเป็นข้อมูล text ส่วนราคาและจำนวนรุ่นจะเป็นข้อมูล numerical และคุณสมบัติต่างๆ จะเป็นข้อมูลแบบผสม
โค้ดถูกเขียนเป็นภาษา Python โดยใช้ library ด้าน data science เช่น NumPy, Scikit-learn, pandas, SciPy
การวัดค่าความคล้ายคลึง (Similarity measure) เป็นวิธีที่หาความใกล้เคียงระหว่างวัตถุสองอย่าง แต่ก่อนที่จะคำนวณค่าได้ จะต้องมีการแปลงข้อมูลเป็นตัวเลข ซึ่งมักจะเก็บในรูปแบบของ matrix และคำนวณโดยใช้ distance metric
Distance metric เป็นการเรียกรวมๆ ของฟังก์ชันในการหาระยะทางระหว่างข้อมูลสองชุด ตัวอย่างวิธีที่ใช้คำนวณ เช่น Euclidean distance ซึ่งมีที่มาจากทฤษฎีบทพีทาโกรัส, Hamming distance ใช้คำนวณระยะทางะหว่าง2 ข้อความที่มีความยาวเท่ากัน เป็นต้น
TEXT SIMILARITY: ตรวจสอบชื่อ-รายละเอียดสินค้า

เนื่องจากข้อมูล text จะไม่สามารถเปรียบเทียบกันได้ จะต้องนำไปแปลงเป็นค่า numerical ก่อน ตามหลัก NLP (Natural language processing) การแปลงข้อมูลดังกล่าวถูกเรียกว่าtext vectorizer
หลักการของการทำ text vectorizer จะเริ่มจากลบข้อมูลรบกวน (noisy data) จากนั้นทำเปลี่ยนประโยคให้เป็นกลุ่มของคำที่เรียกว่า token
เมื่อได้กลุ่มของ tokenแล้ว จะต้องตัดคำที่ไม่มีความหมายสำหรับการเปรียบเทียบออกไป เช่น is, are, in, on ในกรณีของภาษาอังกฤษ
กลุ่ม token สุดท้ายจะถูกนำไปแปลงเป็นข้อมูลnumerical เพื่อคำนวณค่าความคล้ายคลึง ในขั้นตอนนี้มีวิธีคำนวณหลายวิธี เช่น TF-IDF และ count vectorizer
- TF-IDF (Term Frequency-Inverse Document Frequency)
Term Frequency คือจำนวนครั้งที่คำนั้นปรากฏในเอกสาร คำนวณโดยใช้สูตร TF = จำนวนครั้งคำนั้นๆ/จำนวนคำทั้งหมด
Inverse Document Frequency เป็นอีกวิธีการหาความสำคัญของคำ ใช้แนวคิดว่ายิ่งคำนั้นปรากฏน้อย จะยิ่งมีความสำคัญมาก คำนวณโดยใช้สูตร log(จำนวนเอกสาร/จำนวนเอกสารที่มีคำนั้นปรากฏ)
- TF-IDF คือการนำค่าทั้งสองมาคำนวณร่วมกันเพื่อหาคำสำคัญที่ปรากฏมากที่สุด โดยนำค่า TF กับ IDF มาคูณกัน
- count vectorizer คือการนำกลุ่มของtoken มีสร้างเป็นmatrix โดยใช้กลุ่มของคำที่มีเป็นตัวอ้างอิง คำที่มีในประโยคจะถูกตั้งค่าเป็น 1 คำที่ไม่มีจะเป็น 0 เช่น มีกลุ่มของคำ [“This”, “is”, “am”, “are”, “a”, “be”, “test”, “word”, “sentence”] ประโยค “This is a test sentence” จะแปลงเป็น matrix ได้ดังนี้ [1, 1, 0, 0, 1, 0, 1, 0 ,1]
แต่ Commercetool เลือกใช้ Hashing Vectorizer ของ Scikit-learn ซึ่งใช้เวลาในการคำนวณน้อยกว่าและไม่สนใจเรื่องความสำคัญของคำเหมือนTF-IDF เพราะไม่ได้นำมาใช้ในกรณีนี้ (Scikit-learn เป็น library ภาษา Python สำหรับทำ Machine Learning)
NUMERICAL SIMILARITY กรองราคาสินค้า-จำนวนรุ่น

สินค้าตัวเดียวกัน อาจจะมีราคาที่ต่างกัน และสินค้าที่ต่างกันอาจจะมีช่วงราคาใกล้เคียงกัน นอกจากนี้จำนวนรุ่นก็ไม่สามารถใช้เป็นข้อสรุปได้
เพราะสินค้าที่ต่างกันก็มีความเป็นไปได้ที่จะมีจำนวนรุ่นเท่ากัน อย่างไรก็ตามข้อมูลส่วนนี้อาจจะนำไปใช้ประกอบการตัดสินใจได้ในบางกรณี
เนื่องจากข้อมูลเหล่านี้เป็นnumerical วิธีที่ใช้จึงเป็นการปรับค่าให้อยู่ในช่วงระหว่าง [0,1] และใช้distance metric หาความสัมพันธ์
ในการเปรียบเทียบราคาจะต้องแปลงสกุลเงินให้เป็นสกุลเดียวกัน และใช้ค่ามัธยฐานของราคาทั้งหมดของสินค้านั้นเป็นตัวเทียบ
MIXED DATA SIMILARITY สแกนคุณสมบัติสินค้า

ข้อมูลเหล่านี้อาจจะมีรูปแบบเป็นnumerical, nominal, boolean และ multi-valued
ในการทำ distance metric จะใช้ Gower’s distance metric คำนวณความแตกต่างระหว่างค่า และรวมคะแนนแบบมีน้ำหนัก สำหรับค่าที่ไม่มีข้อมูล จะกำหนดให้มีความแตกต่างสูงที่สุด
สำหรับกรณีที่เป็น numericalจะใช้วิธีเดียวกับการเทียบราคา โดยปรับค่าให้อยู่ในขอบเขตเดียวกันแล้วใช้วิธี Euclidean distance คำนวณหาความแตกต่าง ส่วนค่าที่เป็นข้อมูล boolean จะถูกเปลี่ยนเป็นค่า [0,1] และใช้วิธีคำนวณเหมือนกับข้อมูลnumerical
ข้อมูลจำแนกประเภท (categorical)เช่น สี ประเทศ จะใช้วิธีกำหนดให้มีค่าความแตกต่างกันมากที่สุดในกรณีที่มีค่าไม่ตรงกัน แต่ในบางกรณีที่สามารถเปรียบเทียบความใกล้เคียงกันได้
เช่น ความใกล้เคียงระหว่างสีเขียวกับสีเขียวอ่อน จะต้องสูงกว่าสีเขียวเทียบกับสีแดง ในกรณีแบบนี้จะใช้ text disntance เข้ามาช่วยคำนวณด้วย โดยใช้ Levenshtein distance
สำหรับกรณีที่มีค่าหลายค่าในคุณสมบัตินั้น จะใช้ Jaccard distance ในการคำนวณ แต่ก่อนจะเปรียบเทียบ จะต้องตรวจสอบให้ค่าที่เก็บอยู่ในรูปแบบเดียวกันก่อน เช่น S กับ small
สุดท้าย จะต้องหาวิธีการให้น้ำหนักของแต่ละค่าที่สมเหตุสมผลมากที่สุดก่อนนำมารวมเป็นค่าสุดท้าย ซึ่งน้ำหนักที่กำหนดอาจจะต่างกันในแต่ละกลุ่มข้อมูลสินค้า
Methus Bhirakit
Senior Technical Consulting
Source: https://tinyurl.com/yy2qwbzb


